Florence‑2 advances the frontier of unified vision–language modeling by combining a compact seq2seq architecture with massive, multi‑granular annotations to handle captioning, detection, grounding, and segmentation—all via simple text prompts. Trained end‑to‑end on the FLD‑5B dataset (126 M images, 5.4 B annotations) using a single cross‑entropy loss, it achieves state‑of‑the‑art zero‑shot and fine‑tuned performance, matching or exceeding much larger specialist and generalist models. Key innovations include prompt‑based multi‑tasking with location tokens, an iterative data‑engine for scalable high‑quality annotation, and efficient vision encoder initialization.
Table of Contents
Background: The Rise of Unified Vision–Language Models
Contrastive dual‑encoder models like CLIP learn powerful image–text alignments from 400 M pairs, enabling zero‑shot transfer but limited to image‑level outputs [1]. Subsequent hybrids—BLIP‑2’s frozen encoders with Q‑formers [2], Flamingo’s Perceiver‑based cross‑modal layers [3], and Kosmos‑2’s non‑parametric memory integration [4]—expanded capabilities but retained modular or heavyweight designs. Microsoft’s Florence v1 introduced adapter‑based task specialists atop dual encoders [5]. Florence‑2 departs from these by unifying all tasks—captioning, detection, grounding, segmentation—into a single prompt‑based seq2seq framework trained end‑to‑end [6].
Florence‑2 Overview
Seq2Seq Architecture
Florence‑2 employs a DaViT vision encoder to map images (up to 768×768) into token embeddings, which are concatenated with text‑prompt embeddings and fed through a standard transformer encoder–decoder. A single cross‑entropy loss drives all tasks, eliminating specialized heads [6][7].
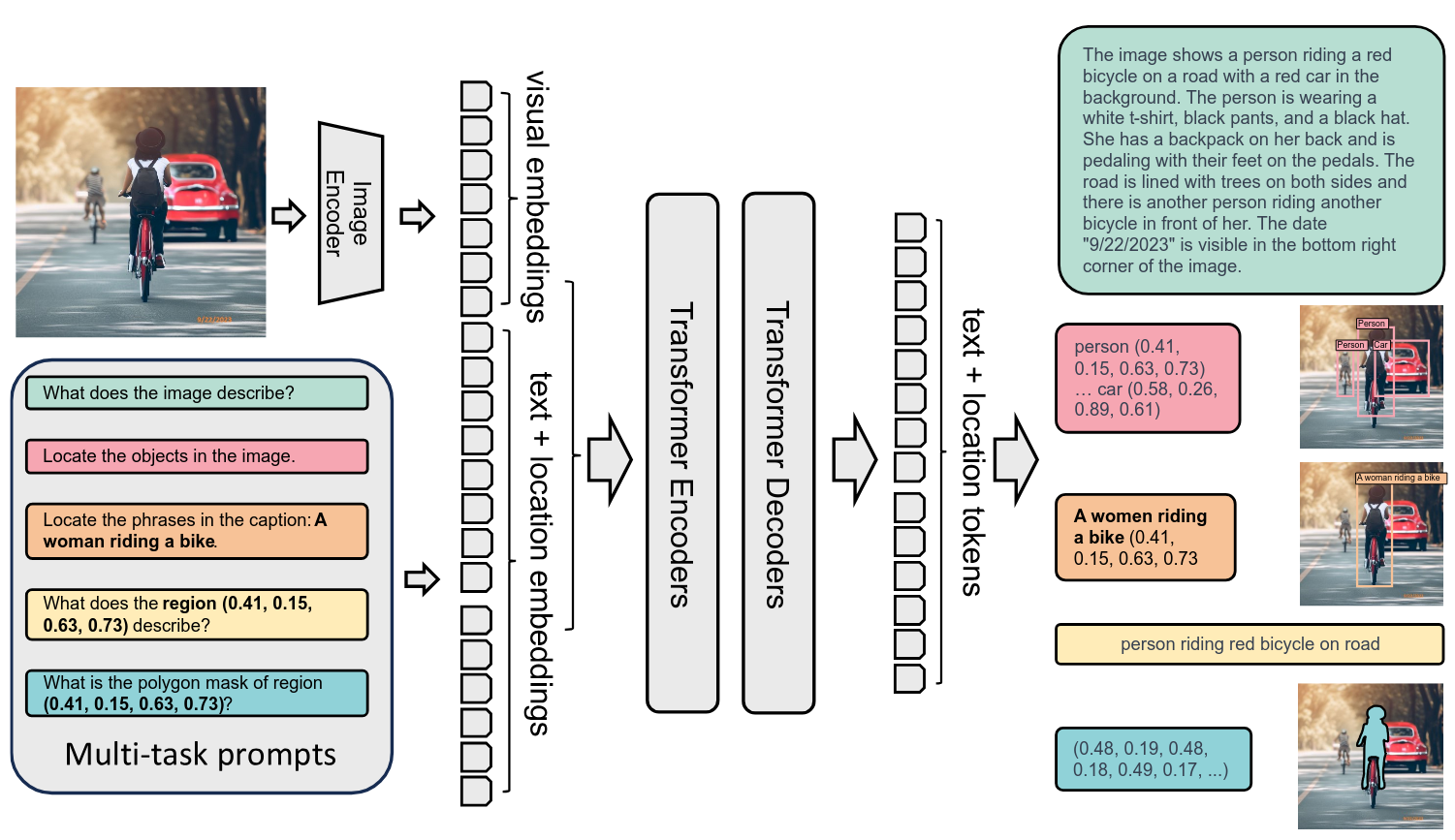
Prompt‑Based Task Formulation
Each vision task is cast as “translation” from image + prompt to text or region tokens. Location tokens (1,000 quantized bins) represent bounding boxes, quadrilaterals, or polygon vertices in the same vocabulary as words. For example, “What objects are in the image?” → “dog at (0.12,0.15,0.48,0.60); cat at …” enables unified detection and grounding [6].
FLD‑5B Dataset & Data Engine
The FLD‑5B dataset comprises 126 M images with 500 M captions, 1.3 B region–text pairs, and 3.6 B phrase–region triplets, spanning coarse to fine spatial and semantic levels [6].
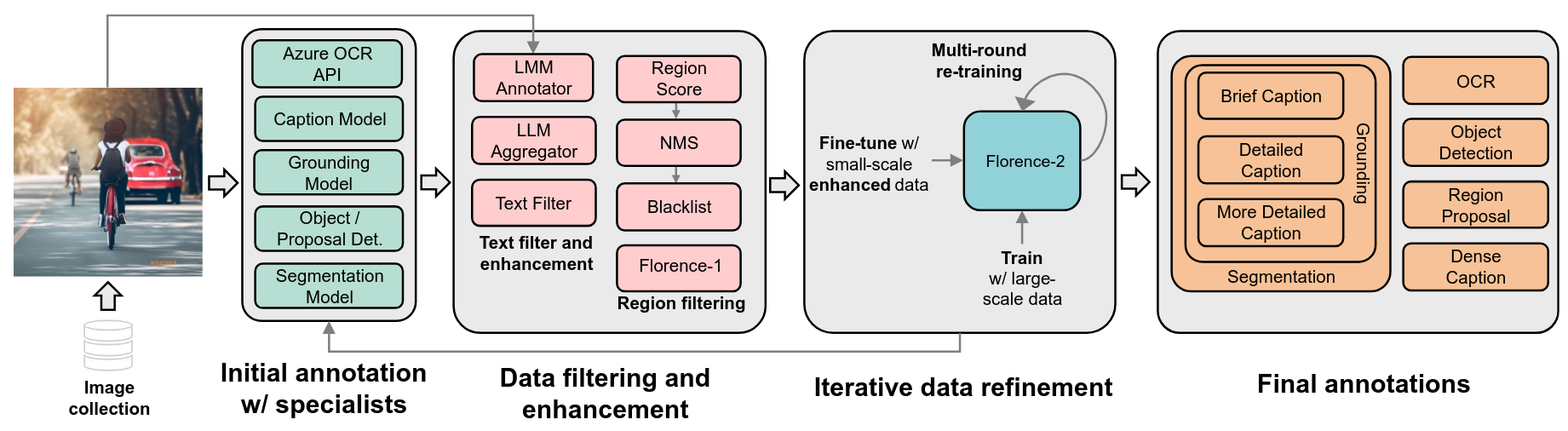
Annotations are generated via:
- Initial annotation by specialist models (detectors, captioners).
- Filtering & enhancement using confidence thresholds, non‑max suppression, and LLM‑based refinement.
- Iterative refinement, where updated Florence‑2 models re‑annotate to close coverage gaps [6][8].
Experimental Highlights
Zero‑Shot Performance
| Task | Florence‑2‑L | Flamingo (80B) | Kosmos‑2 (1.6B) |
|---|---|---|---|
| COCO Caption (CIDEr) | 135.6 | 84.3 | – |
| Flickr30k R@1 | 56.3 | – | 52.3 |
| RefCOCO–RES (mIoU) | 35.8 | – | – |
Florence‑2‑L (0.77 B params) outperforms Flamingo‑80B on COCO captioning and achieves strong grounding/segmentation metrics unseen in prior VLMs [7].
Unified Fine‑Tuning
Fine‑tuning one Florence‑2 model on COCO, VQA, RefExp, etc., yields a generalist that rivals specialist models:
- Captioning & VQA: Florence‑2‑L attains 143.3 CIDEr and 81.7 VQAv2, on par with 7.8 B BLIP‑2 and 2.1 B CoCa [9].
- Region Tasks: On RefCOCO, speaks 95.3 R@1 and 91.7 mAP, surpassing PolyFormer and UNINEXT [10].
Ablation Studies & Insights
- Multi‑Granular Training: Combining image‑, region‑, and phrase‑level signals outperforms using any single granularity [6].
- Prompt Engineering: Task‑specific prompts boost accuracy over generic queries, underscoring the value of careful prompt design [6].
- Vision Encoder Init: Initializing DaViT from MAE self‑supervision yields ~3–4 CIDEr gain over random or CLIP init [11].
- Resolution Diversity: High‑resolution fine‑tuning adds ~2 CIDEr and ~1.5 mIoU, indicating spatial detail improvements [12].
Conclusion
Florence‑2 sets a new standard for unified vision–language foundation models by demonstrating that a compact seq2seq architecture, when paired with an iterative, large‑scale annotation engine, can match or exceed much larger specialist systems across a wide array of tasks. Its success highlights the promise of prompt‑based multi‑task learning and scalable data engines for future generalist AI.
References
- Radford et al., “Learning Transferable Visual Models From Natural Language Supervision,” ICML 2021.
- Li et al., “BLIP–2: Bootstrapping Language–Image Pre-training with Frozen Image Encoders and Large Language Models,” arXiv:2301.12597 2023.
- Alayrac et al., “Flamingo: a Visual Language Model for Few-Shot Learning,” NeurIPS 2022.
- Huang et al., “Kosmos‑2: Grounding Multimodal Language Models in Non-Parametric Memory,” arXiv:2306.05837 2023.
- Li et al., “Florence: A New Foundation Model for Computer Vision,” arXiv:2111.11432 2021.
- Xiao et al., “Florence‑2: Advancing a Unified Representation for a Variety of Vision Tasks,” CVPR 2024, arXiv:2311.06242.
- Xiao et al., Table 3, “Zero-shot performance of generalist vision foundation models,” CVPR 2024.
- Xiao et al., Section 4, “Data Engine,” CVPR 2024.
- Xiao et al., Table 4, “Performance of specialist and generalist models on captioning and VQA tasks,” CVPR 2024.
- Xiao et al., Table 5, “Performance of specialist and generalist models on region-level tasks,” CVPR 2024.
- Ding et al., “DaViT: Dual Attention Vision Transformers,” ECCV 2022.
- Sunidhi Ashtekar, “All You Need to Know About Florence‑2!”, Medium 2023.